| Edith Cohen |
Jeffrey D. Oldham |
| AT&T Labs-Research | Computer Science Dept. |
| 180 Park Avenue | Stanford University |
| Florham Park, NJ 07932 USA | Stanford, CA 94305 |
| {edith,hkl}@research.att.com | oldham@cs.stanford.edu |
Edith Cohen
![]() Haim Kaplan
Haim KaplanJeffrey D. Oldham
AT&T Labs-Research
Computer Science Dept.
180 Park Avenue
Stanford University
Florham Park, NJ 07932 USA
Stanford, CA 94305
{edith,hkl}@research.att.com
oldham@cs.stanford.edu
March 1, 1999
Hyper Text Transfer Protocol (HTTP) traffic dominates Internet traffic. The exchange of HTTP messages is implemented using the connection-oriented TCP.
HTTP/1.0 establishes a new TCP connection for each HTTP request, resulting in many consecutive short-lived TCP connections. The emerging HTTP/1.1 reduces latencies and overhead from closing and re-establishing connections by supporting persistent connections as a default.
A TCP connection which is kept open and reused for the next HTTP request reduces overhead and latency. Open connections, however, consume sockets and memory for socket-buffers. This trade-off establishes a need for connection-management policies.
We propose policies that exploit embedded information in the HTTP request messages, e.g., senders' identities and requested URLs, and compare them to the fixed-timeout policy used in the current implementation of the Apache Web server.
An experimental evaluation of connection management policies at Web servers, conducted using Web server logs, shows that our URL-based policy consistently outperforms other policies, and achieves significant 15%-25% reduction in cost with respect to the fixed-timeout policy. Hence, allowing Web servers and clients to more fully reap the benefits of persistent HTTP.
Keywords: HTTP, persistent connections, TCP, connection management, caching
The Hypertext Transfer Protocol (HTTP) dominates information exchange through the Internet. HTTP messages are transported by TCP connections between clients and servers. Most implementations of HTTP/1.0 [6] use a new TCP connection for each HTTP request/response exchange. Hence, the transmission of a page with HTML content and embedded images involves many short-lived TCP connections.
TCP connection is established with a 3-way handshake; and typically several additional round trip times (RTT) are needed for TCP to achieve appropriate transmission speed [34]. Each connection establishment induces user-perceived latency and processing overhead. Thus, persistent connections were proposed [31,19,32] and are now a default with the draft HTTP/1.1 standard [17,18]. HTTP/1.1 keeps open and reuses TCP connections to transmit sequences of request/response messages; hence, reducing the number of connection establishments and resulting latency and processing overheads.
Deployment of HTTP/1.1 necessitates policies for deciding when to terminate inactive persistent connections. HTTP/1.1 specifies that connections should remain open until explicitly closed, by either party. Beyond that HTTP/1.1 provides only one example for a policy, suggesting using a timeout value beyond which an inactive connection should be closed [18, §8.1.4]. A connection kept open until the next HTTP request reduces latency and TCP connection establishment overhead. However, an idle open TCP connection consumes a socket and buffer space memory. The minimum size for a socket buffer must exceed the size of the largest TCP packet, i.e., 64Kb, and many implementations pre-allocate buffers when establishing connections [30]. The number of available sockets is also limited. Many BSD-based operating systems have small default or maximum values for the number of simultaneously-open connections (a typical value of 256) but newer systems are shipped with higher maximum values (typically thousands). Studies show, however, that with current implementations, large numbers of (even idle) connections can have a detrimental impact on server's throughput [2,3,4].
The design challenge of good connection-management policies is to strike a good balance between benefit and cost of maintaining open connections and to enforce some quality of service and fairness issues. The current version 1.3 of the Apache HTTP Server [1] uses a fixed holding-time for all connections (the default is set to 15 seconds), and a limit on the maximum allowed number of requests per connection (at most 100). (Limiting the number of request was proposed in [19] and provides some fairness.) The Apache implementation is a quick answer to the emerging need for connection management. The wide applicability and potential benefit of good connection-management makes it deserving further study.
Persistent connection management is performed at the HTTP-application layer. Current implementations of Web servers use a holding-time model rather than a typical caching model. Using holding-times, a server sets a holding time for a connection when it is established or when a request arrives. While the holding-time lasts, the connection is available for transporting and servicing incoming HTTP requests. The server resets the holding-time when a new request arrives and closes the connections when the holding-time expires. In a caching model there is a fixed limit on the number of simultaneously-open connections. Connections remains open (``cached'') until terminated by client or evicted to accommodate a new connection request. A holding-time policy is more efficient to deploy due to architectural constraints whereas a cache-replacement policy more naturally adapts to varying server load. Policies in the two models are closely related when server load is predictable [10]; A holding-time policy assigning the same value to all current connections is analogous to the cache-replacement policy LRU (evict the connection that was Least Recently Used). In fact, under reasonable assumptions the holding-time value can be adjusted through time as to emulate LRU under a fixed cache size (and hence adapt to varying server load) [10]. Heuristics to adjust the holding-time parameter were recently proposed and evaluated on server logs [15].
A critical component in the effectiveness of connection-management policies in both models is the ability to distinguish connections that are more likely to be active sooner. LRU exploits the strong presence of reference locality but does not use further information to distinguish between connections. We propose policies based on various attributes of HTTP request messages, and compare them to LRU.
Our policies design was guided by a basic framework, which assumes an associated distribution function on the next-request-time for each open connection. Holding-time values or (analogously) eviction decisions are determined based on these distributions. This framework was previously used in various contexts (for example, holding-times for IP over ATM virtual circuits [25], spinning on a lock in a shared memory multiprocessor [24], adaptive disk spindown [27], and Web proxy caching [12].) Theoretical analysis and polices were given in [10,24,27,28]; an optimal policy in the holding-time model was given in [24,25,10]; and an optimal policy in the caching model, for predictable load conditions, was provided in [10]. The optimal policy in this context uses knowledge of the distributions in the best possible way.
Since such distributions are not explicitly available, the framework is deployed using heuristics. Our general methodology is to first identify an attribute of HTTP requests that is correlated with the time to the next-request; For each reasonably frequent value of the attribute, we estimate following inter-request time distribution from a sample data; The estimated distributions are then substituted in the ``optimal'' policy to assign holding-times. Performance of these derived policies highly depends on the selected attribute, and on the size and relevance of the sample.
An important issue was to obtain a good estimate of the distribution for less-frequent attribute values. We developed a heuristic that uses a weighted-sum of samples from the conditional distribution (for particular attribute value) with a richer sample obtained over all attribute values. This heuristic was critical for the performance of our policies and we suspect it may be valuable in other applications.
Connection management policies can assign timeout values based on attributes present in HTTP requests and responses. For example, requested URL, the referrer URL, and content type. Using the framework above, we obtain and compare policies utilizing different attributes. Our study centered on policies at Web servers. HTTP/1.1 permits either party to terminate a connection. Web servers, however, are typically the busier party, with larger incentives for tighter connection management. Our evaluation was performed using server logs obtained from AT&T's Easy Word Wide Web service [14]. Since HTTP/1.1 is not widely deployed, available logs are for HTTP/1.0 traffic, which do not utilize persistent connections. Deployment of persistent HTTP and pipelining may mostly impact ordering and decrease inter-request times between requests for embedded contents, but longer inter-request times are unlikely to be significantly affected. Thus, changes due to HTTP/1.1 deployment are unlikely to significantly affect our conclusions. To further confront the issue, we simulated the various policies on both the original logs and clicks logs, which factor out intervals due to embedded contents, but preserve user think times. Clicks logs attempt to capture traffic patterns with persistent high bandwidth connections.
Our experimental results were consistent across server logs and for both variants of each log; hence, substantiating the soundness and applicability of our conclusions. Our URL-based policy uniformly provided better performance trade-offs than other policies we considered. On the original logs, compared with LRU (or fixed holding-time policy implemented at the Apache server), our adaptive policy used 15%-25% fewer open connections (on average) while incurring the same number of connection establishments; and required 10%-25% fewer connection-establishments when using the same average amount of open connections. Even more significant reductions, typically around 50%, are achieved on the clicks logs. The resulting performance improvement is considerable, since connection-establishments induce user-perceived latency and overhead [16,31,23] wheras large number of open connections is both detrimental to throughput [4] and is more likely to reach the server's hard-set limits, causing it to refuse new connections.
In Section 2 we discuss the interaction between HTTP and TCP at Web servers, and the nature of server-logs data. We then describe the logs used in our evaluation. Last, we discuss issues with the use of HTTP/1.0 traffic logs, and our solutions. Section 3 contains our cost model. Section 4 describes how a policy should use an estimate of the distribution of the time to the next request from the same client in making holding-time decisions. This section allows for detailed understanding of our connection management policies. The overall presentation however, permits the reader to proceed with later sections before reading Section 4. Section 5 lists the various connection management policies we evaluated. In Section 6 we provide experimental results and conclusions. Section 7 concludes with proposals for future research directions.
Top-level management of persistent connections is performed at the HTTP server application, and hence, may depend only on information available to the application. In particular, holding-times directives are determined when response contents are placed in the socket, and not, for example, when transmission ends.
Management of persistent connections at the server application amounts to determining a holding-time during which the connection remains open awaiting additional HTTP requests. The server resets the holding-time when a new request arrives.
Our evaluation was performed using Web server logs. For each HTTP request, the logs provide the IP address of the requesting client, the requested URL, a time stamp (in whole seconds), the HTTP response code, the referrer field (if available), and some additional information. The logged time is usually one of the followings: the time when the server starts processing the request, the time when the server starts writing the response contents into the socket buffer, or the time when the server completes writing the response contents into the socket. The exact choice varies by server software, and the times of the other two events are not recorded.
The actual choice which of the three times above is recorded has little significance for our purposes. The elapsed time of the internal server operation of processing the requests and writing the response, is fairly small with respect to transmission time, reasonable holding-time values, and to the 1-second granularity of the time stamps. Therefore, whatever the exact logged time is, it must be close to the time when the HTTP session makes connection management decisions. Further discussion on properties of server logs can be found in [26].
| label | site characterization | requests | clients | resources |
| L1 | Organization | 946953 | 33101 | 1906 |
| L2 | Multimedia equipment retailer | 1583776 | 60747 | 244 |
| L3 | Fashion retailer | 3921767 | 58838 | 347 |
| L4 | Magazine | 1550162 | 140920 | 245 |
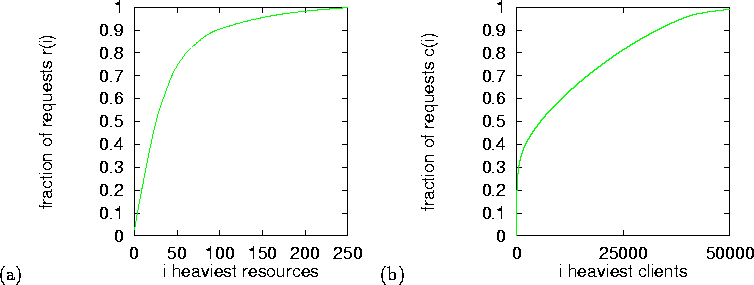
Figure 1(a) shows the cumulative fraction r(i) of the requests for the i most frequently requested resources (URLs) in L3. Figure 1(b) shows the cumulative fraction c(i) of the requests sent by the i clients with the largest number of requests in L3. The corresponding distributions for L1, L2, and L4 are similar. We can see that about 1/5 of the resources are responsible for 80% of the requests where 1/5 of the clients is responsible only for 50% of the requests. Server logs exhibit asymmetry between clients and resources (observed also when the number of resources is large). Most of the requests are made to frequently-requested resources (resource popularity is Zipf like) whereas a large part of requests are made by transient clients. These observations reflect known phenomena and are relevant for designing connection management policies based on client-history and URL.
 |
Deployment of HTTP/1.1 is expected to decrease inter-request spacings. Pipelining of requests on the same persistent connection may further decrease spacings. Pipelining is supported by HTTP/1.1 but does not seem to be implemented yet by popular browsers [36]. The decrease in spacings is likely to be more noticeable for shorter inter-request time intervals. Shorter intervals are typically due to requests for embedded contents, whereas longer intervals reflect ``user think times'' or transmission time. Reasonable connection management policies are likely to maintain persistent connections open for at least a short amount of time following the last request. The TCP TIME_WAIT state [35] implies that closed connections consume resources from 60-240 seconds past their closing time; factoring this in the overhead cost of a new connection establishment, we obtain that the latter compares with open-cost of the order of a minute or more. Thus, supporting the use of longer holding times.
The performance difference between various policies therefore stems from their actions on longer intervals. Hence, the direct use of existing HTTP/1.0 logs is expected to yield meaningful results.
To further substantiate this, we simulate the different persistent connection management policies on both
We expect future HTTP/1.1 request patterns to be in between the HTTP/1.0 log and the clicks log. Consistent results across both these extremes suggest robustness and applicability of our conclusions.
HTTP transfers are often facilitated by a client opening multiple concurrent TCP connections. The maximum number of connections to one server is a browser-configurable parameter, and defaults to 4 concurrent threads [29] in HTTP/1.0 implementations of the Netscape Navigator browser. The suggested number is 2 concurrent persistent TCP connections with HTTP/1.1 [17,18]. Microsoft Explorer seems to indeed use up to 2 connections whereas Navigator seems to use up to 6 concurrent connections [36].
Available server logs, unfortunately, do not provide information on the number of active connections. The information could be retrieved from the times each HTTP response is received and acknowledged by the client, but these times are not available. Our evaluation therefore assumed a single active connection for each client. We note that our attribute-based policies essentially ``learn'' policies from sample data, and their performance could only improve if the different connections are distinguished.
We use the following holding-time cost model. Upon receiving an HTTP request r, the server decides on a holding-time interval T(r). The server then leaves the connection open for at most T(r) seconds from the moment it received r. If a new request r' arrives within the next T(r) seconds, then a new holding-time interval T(r') is in effect. Otherwise the connection is terminated after T(r) seconds.
A connection management policy is an algorithm that determines an interval T(r) for every request r. Consider a request sequence s. The profit (number of hits), pA, of a policy A on s is the number of requests that did not require opening a new connection. The number of misses, mA, of A on s is the number of requests that required opening a new connection. The open-cost, HA, of a policy A is total time connections were open. The policy used by HTTP/1.0 closes the connection after every request thereby incurring a miss for each request and minimal open-cost. Another extreme is a policy that never closes connections incurring a minimal number of misses and very high open-cost. We are looking for policies between these two extremes, that generate good trade-offs between the number of misses and the open-cost.
We parameterize policies by a threshold V that governs trade-offs between open-cost and number of misses. For all policies considered here, both open-cost and profit increase with V, whereas the number of misses decrease with V. This follows from the fact that for all policies T(r) increases with V for every r. We compare the misses to open-cost trade-offs generated by various policies. The open-cost (when divided by elapsed time) measures the average number of open connections.
Minimizing misses is important since HTTP requests necessitating connection establishments endure longer user-perceived latency; and connection establishments and closings incur processing and memory overhead. The per-connection overhead includes socket buffers allocation/deallocation and memory, periodic processing, and port number consumed when the connection is in TIME_WAIT state, which lasts 60 seconds (for BSD-based implementations) to 240 seconds (as specified in [8]) past the closing time of the connection [35]. On the other hand, small open-cost is important since the number of open connections is subjected to hard-set limits and large numbers of (even idle) open connections degrade server throughput [4].
Keshav et al [25] studied a closely related cost model.
A parameter ![]() governs the relative costs of opening a connection and
connection open time. The
cost of a policy A is defined as its open time
plus the total cost for opening connections. That is
governs the relative costs of opening a connection and
connection open time. The
cost of a policy A is defined as its open time
plus the total cost for opening connections. That is
![]() . Keshav et al
compared the cost of various policies while varying the
value of the parameter
. Keshav et al
compared the cost of various policies while varying the
value of the parameter ![]() .
This model is related to ours by capturing the same trade-offs;
as we shall see, the policy MPG described in section 4
minimizes CA when we set the parameter V to be
.
This model is related to ours by capturing the same trade-offs;
as we shall see, the policy MPG described in section 4
minimizes CA when we set the parameter V to be ![]() .
.
Another natural cost model for connection management is a regular caching model where we have a fixed capacity k on the number of open connections we can hold. Once a connection needs to be established and the cache is full the policy has to decide and close one of the currently open connections. The goal is to maximize profit.
The holding-time model and the caching model are closely related. There exists correspondence between policies in the two models and their relative performance [10]. If the holding-time policy is adjusted to maintain a near-steady number of open connections, then the open-time cost measure corresponds to cache size (when divided by elapsed time). In [10] it is shown that under reasonable assumptions, experimental results on the relative performance of policies in one model indicate a similar relation between the analogous policies in the other model.
Because of architectural and implementation reasons (see Section 2.1), the first model seems to be a likely implementation for Web server based persistent connection management.
It is possible to summarize the actions of a policy B with
a parameter V
by a mapping from the set of all possible
requests S (triples (cr,tr,Fr)) to a probability density function
![]() that captures the likelihood that upon encountering a
request at time tr with associated probability Fr,
B keeps an open connection to cr for time period t.
that captures the likelihood that upon encountering a
request at time tr with associated probability Fr,
B keeps an open connection to cr for time period t.
Let r be a request from client cr
with associated distribution function Fr.
The expected profit (number of hits)
of keeping a connection to cr for time length t
following r is ![]() and the corresponding
expected cost (connection time) is
and the corresponding
expected cost (connection time) is ![]() .It follows from linearity of expectation that the expected profit of B
is
.It follows from linearity of expectation that the expected profit of B
is
![]()
![]()
For a request r we define
The policy Minimum Profit Gradient (MPG) upon receiving
r keeps the connection open
for
![]() That is, TV(r) is the maximum point such that for every y< TV(r),
the expected cost of
increasing the caching period from y to TV(r) divided
by the expected profit gain from this increase is no greater than V.
That is, TV(r) is the maximum point such that for every y< TV(r),
the expected cost of
increasing the caching period from y to TV(r) divided
by the expected profit gain from this increase is no greater than V.
By the above definition,
the policy MPG with
parameter V minimizes the expected cost ![]() when A ranges over the set of all policies
that know the probability distribution Fr for every request r.
This corresponds to choosing
when A ranges over the set of all policies
that know the probability distribution Fr for every request r.
This corresponds to choosing ![]() in the Keshav et al cost
model mentioned in Section 3.
in the Keshav et al cost
model mentioned in Section 3.
Given a distribution function F(t), there is a discrete set of time
intervals that corresponds to choices that MPG can make (on the
range of ![]() threshold values) for
caching a connection to client cr
with associated distribution
threshold values) for
caching a connection to client cr
with associated distribution ![]() .
We partition the domain of F(t) into
intervals I1=[0,t1], I2=(t1,t2],
.
We partition the domain of F(t) into
intervals I1=[0,t1], I2=(t1,t2], ![]() where
t1 is the maximum z>0 that maximizes the quantity
where
t1 is the maximum z>0 that maximizes the quantity
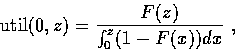
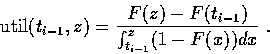
Lemma 4.1 [10]
An equivalent alternative definition for the choice of
policy MPG is to keep a connection to cr for an
interval [0,ti] for the maximum i such that ![]() .
.
Policy MPG yields optimal trade-offs of profit to open-cost in the sense of the following theorem.
Theorem 4.2 [10]
For every caching policy B that knows the distribution Fr for every
request r (but not
the actual sequence drawn)
there exists values ![]() and
and ![]() such that
such that
![]() and
and
![]() .
.
Performance depends on choice of attributes, in particular, their number, interdependence, and correlation with the next request time. Examples of attributes available with HTTP requests are the requesting client, requested URL, and referrer URL. Our evaluated policies utilizes at most two attributes at a time.
The ``learned'' distribution is obtained by first collecting a histogram on inter-request times, and then smoothing it by taking a weighted average with the general inter-request time histogram.
A good choice of attributes and sample size is such that for most requests, there is a sufficient amount of sample data with the applicable attribute values. With more sample data containing requests for a URL u we are able to obtain more confident estimates for the inter-request time distribution following requests for u. For some attribute-values, however, there inherently may not be sufficient data. For example, when considering URLs in fast changing sites or when using the client attribute: Large fraction of requests originate by transient clients which were not seen recently and for which there are only short or no histories available.
A small sample may still carry important information. The following example demonstrates, however, that when small samples are used without smoothing, the effectiveness of distribution-based policies suffers. Suppose we have 4 requests to a URL u in the sample data, with all 4 inter-request times being 2 seconds and below. If the unsmoothened sample histogram is provided as input to MPG, then MPG always selects holding times of at most 2 seconds, since it associates zero expected profit for an increase to a longer holding time. The sample, however, could be a likely outcome from a ``true'' distribution with 10% likelihood of inter-request times between 2 and 10 seconds; and if so the MPG policy would incurs a miss-rate of at least 10% on all requests made to the URL u, even for large values of V.
Thus, we deployed the following smoothing heuristic to derive the
associated distributions.
Consider a resource u for which we have n samples.
Let Ru be the distribution
function obtained by dividing the histogram of
inter-request intervals following requests for u, by n.
Similarly, let G be the distribution function
obtained in this manner across all available requests.
Instead of using the distribution ![]() we used
we used
![]()
Our smoothing scheme is inspired by empirical Bayesian inference methods where the generic distribution G is to be thought of as the prior distribution and Fu is the posterior distribution which we obtain using the prior and the data represented by Ru [7,20]. Smoothing was crucial for obtaining good policies in our evaluation.
In Section 5.3 we describe the various connection management policies we derived using this framework.
Least Recently Used (LRU) is a common cache replacement algorithm.
When
a request for a new item arrives and the cache is full, LRU
evicts the cached item that was accessed least recently.
LRU exploits the high locality of reference usually exhibited
in request sequences, and performs well in practice. Classical
theoretical results establish that
LRU is ![]() -competitive against the optimal
offline algorithm with cache of size
-competitive against the optimal
offline algorithm with cache of size ![]() [33].
[33].
The policy analogous to LRU in the holding-time model is the one that uses the same interval T(r) for every request r [10,25,12]. Hereafter we use the name LRU for this policy. LRU is parameterized by the constant V to which T(r) is set.
As a benchmark we consider the performance of an omniscient
optimal policy. The optimal policy
knows the sequence in advance and achieves the
best trade-offs of misses and open-cost. In the caching mode,
Belady's algorithm [5], which evicts the page to be used
furthest in the future, is known to be optimal. The
optimal policy OPT in the holding-time model is the following.
Let I(r) be the length of the inter-request interval
from r to the following request.
Fixing a threshold V, the optimal policy OPT,
sets T(r)=I(r) if ![]() and T(r) = 0 otherwise.
If
and T(r) = 0 otherwise.
If ![]() is the open-cost and
is the open-cost and ![]() is the profit of OPT
with threshold V then it is easy to see that no policy
can have profit exceeding
is the profit of OPT
with threshold V then it is easy to see that no policy
can have profit exceeding ![]() for a cost no larger
than
for a cost no larger
than ![]() .
.
Our attribute-based policies are motivated and derived using the framework
described in Section 4.
An attribute-based policy for attributes A1,A2 (e.g., requested
URL and referrer URL) is captured by a mapping
![]() from possible values of A1,A2 to
holding-times.
The connection management policy uses a holding-time of
MVA1,A2(u1,u2) following all requests with
attribute values A1=u1 ,A2=u2.
The parameter V corresponds to the relation
between the cost of establishing a new TCP connection and
the cost of maintaining an idle open connection for a period of time.
For any fixed set of values,
the holding-time is non-decreasing with V and is actually
a step function.
Performance trade-offs for each policy are obtained by sweeping V.
We evaluated policies derived from the following attributes.
from possible values of A1,A2 to
holding-times.
The connection management policy uses a holding-time of
MVA1,A2(u1,u2) following all requests with
attribute values A1=u1 ,A2=u2.
The parameter V corresponds to the relation
between the cost of establishing a new TCP connection and
the cost of maintaining an idle open connection for a period of time.
For any fixed set of values,
the holding-time is non-decreasing with V and is actually
a step function.
Performance trade-offs for each policy are obtained by sweeping V.
We evaluated policies derived from the following attributes.
The holding-time used for
the jth request for a client c is
![]() , where h<j is largest such that
, where h<j is largest such that
![]() is defined.
is defined.
The CLIENT policy uses the same information as Jacobson's estimated exponentially weighted mean and variance policy [21]. Jacobson's policy, and also a version of our CLIENT policy was evaluated by Keshav et al [25] for circuit holding-times of IP traffic over ATM.
The mapping describing each attribute-based policy is constructed using log data. The construction can be performed either online or by a periodic off-line processing of a subset of the server log. An online construction may be timely whereas an off-line one minimizes run-time computation overhead.
Our evaluation was for an off-line construction. We partitioned the logs into two parts of approximately the same size. Each part contained the request sequences of (a random) half of the clients. Policies were evaluated on one part of the log (``test data''). For all but for the CLIENT attribute, the mappings were computed once using the other part of the log (``learning data'').
Sensitivity analysis described in Section 6 shows that policies derived from learning data containing only a small fraction of clients yield comparable results. We observed that access patterns in our logs were fairly static through time. Hence, our off-line construction obtained good results (learning data derived on-line from very-recent history is likely to be more effective for more dynamic sites).
For CLIENT we simulated an online policy utilizing the accumulated available history of each client. This online construction is more appropriate for the CLIENT attribute, since clients are very transient, and many requests are due to clients that only had a short interaction with the server over a long period of time (see Section 2.3). Hence, a periodic analysis would not provide sufficient per-client data.
The computational cost of constructing a policy (deriving the mapping MV)
is linear in the size of the learning data and involves a single pass.
A histogram of inter-request times is collected for
every set of attribute values ![]() . A generic
histogram, across all requests, is also collected.
. A generic
histogram, across all requests, is also collected.
The resulting policy is represented by the mapping MVA1,A2(u1,u2) from sets of attribute-values to holding-times. The mapping can be stored in a hash-table to facilitate a quick assignment of holding-times to requests. The size of the hash-table depends on the number of distinct sets of values considered, and can widely vary for different attributes and between Web sites.
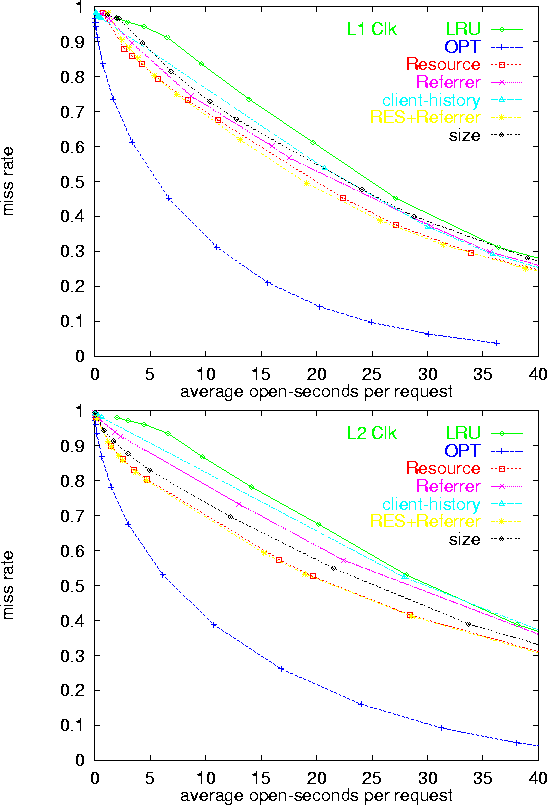
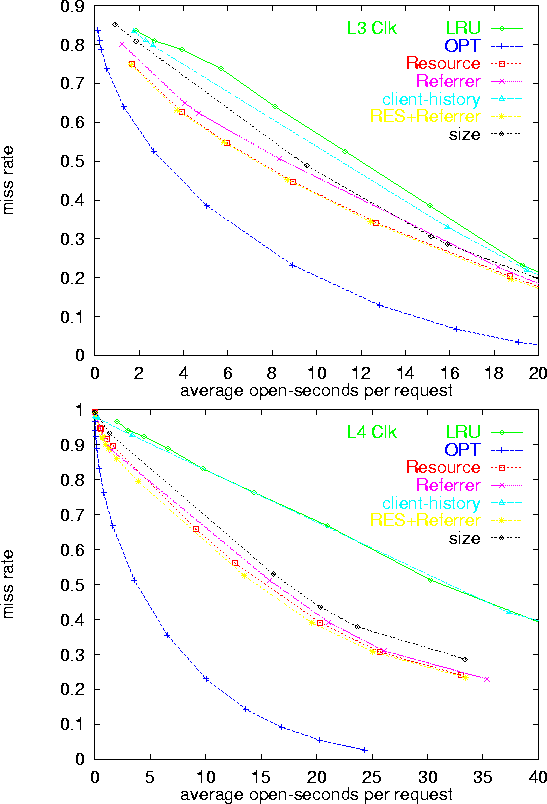
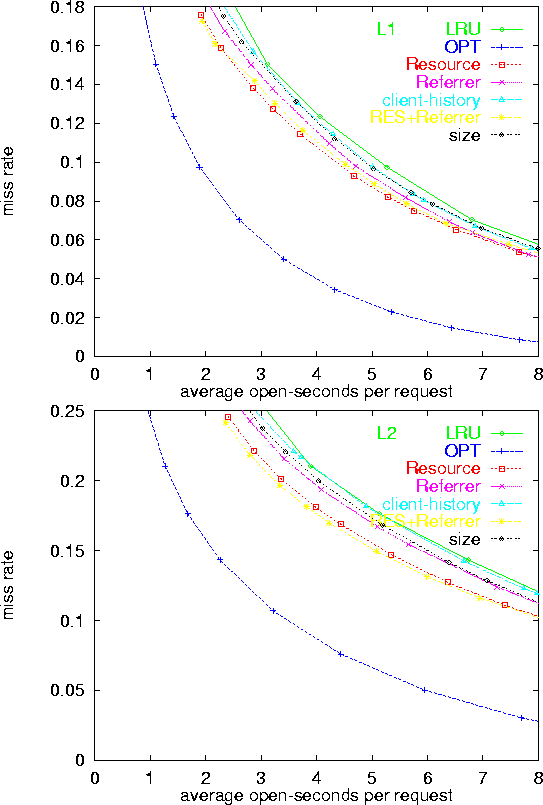
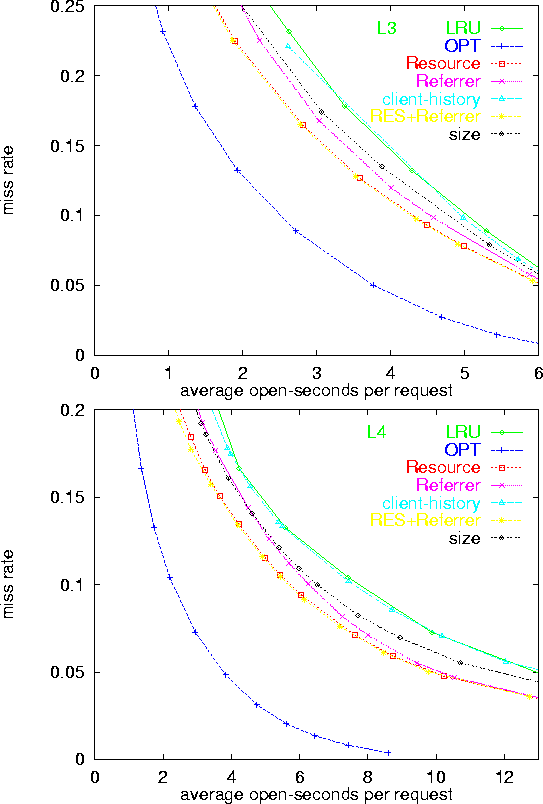
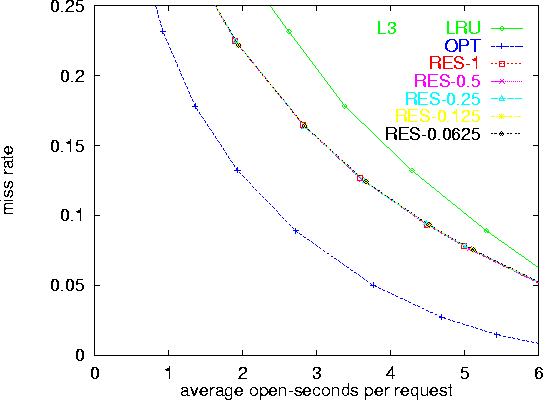
The y-axis (miss rate) represents the fraction of requests for which a persistent connection was not available (In other words, the ratio of connections establishments to requests). The measurements are restricted to requests where the previous request by the same client had occurred no longer than 10 minutes before. The x-axis (average open time per request) corresponds to the total combined time connections were open divided by the total number of requests. Note that this corresponds to the average number of open connections divided by the average request rate.
As expected, the plain LRU policy was outperformed by attribute-based policies. The RESOURCE policy was consistently the best (or nearly the best) performer, across all server logs, and for both the original logs and the clicks logs. The policies REFERRER and SIZE often approach the performance of RESOURCE, but never exceed it.
The observations that REFERRER performs close to RESOURCE, but that the combined policy RES-REF does not generally outperform RESOURCE, indicates that the REFERRER attribute indeed carries a lot of the information present in the RESOURCE attribute, but does not carry significant additional useful information for predicting lengths of inter-request intervals. This is due to the fact that on the logs we considered, most requests for a typical resource (URL) had the same referrer. Hence, by and large, values of the resource attribute constitute a finer sub-partitioning of the partition obtained by values of the referrer attribute.
The SIZE policy partitioned response sizes to about 30 bins each corresponding to a range of sizes. The bins were mapped to holding-time intervals. If response size is indeed correlated with inter-request time, we expect assigned holding-times to generally be longer for bins of larger response sizes. A close look at these mappings, however, shows that this is far from being the case. The actual explanation to the good performance of SIZE is the fact that most requests in a typical bin were due to a small number of URLs (sometimes a single URL), and hence, SIZE was actually mimicking the RESOURCE policy on these bins.
The client-history policy CLIENT yields marginal improvements, if at all, over LRU, indicating that unlike the situation in other contexts (e.g., IP over ATM [25]), each client's overall history with the server is not a significant hint for predicting the clients future inter-request intervals. The identity of the requested URL provided a much more meaningful hint for the duration of the inter-request interval. The CLIENT policy also suffers because typically there are many transient clients each having a single or few short interactions with the server. Thus, there is a very short history available for a large fraction of the requests. On such requests, the policy applies the generic holding-time and CLIENT reduces to LRU.
The consistent results obtained across all servers and for both the clicks logs and the original logs suggest that our conclusions and results are fairly robust. In particular, we expect them to be similar for data that incorporates persistent connections. Results were also consistent across a wide range of open-cost values, suggesting robustness for varying load and server capacities.
The overall-best policy, RESOURCE, achieved significant improvements over LRU. Consider the logs L1, L2, L3, and L4, respectively, and the use of a fixed 15 seconds holding-time interval (the default in the current implementation of the Apache HTTP server code). The corresponding ``miss rates'' are 12.4%, 17.6%, 13.2% and 13.2%. The respective normalized open-costs are 4.05 seconds, 5.13 seconds, 4.28 seconds, and 5.6 seconds per request. The RESOURCE policy achieves the same miss rate with normalized open-costs of 3.22, 4.38, 3.5, and 4.2 seconds per request, respectively. Hence, achieving reductions of 20%,15%, 16%, and 25% in total open time (equivalently, in average number of open connections) with respect to LRU.
The reduction in cost with respect to LRU is even more significant on the clicks logs. On the L4 log, for example, fixed holding-times of 34 and 51 seconds result in respective normalized costs of 30 and 43 seconds, and miss rates of 51% and 37%, respectively. The RESOURCE policy achieves these miss rates with respective costs of 15 and 23 seconds, which constitutes improvements of about 50% over LRU. As can be seen from Figures 4 and 5, other logs exhibit similar results.
When a relatively small number of resources dominates a large fraction of requests, as is typical in server logs, a smaller amount of learning data suffices for RESOURCE to perform well. Figures 2-5 plot performance of policies when the learning data set included half the clients. Figure 6 shows that performance does not degrade when the learning data contains only 1/32 of the clients. The mapping of resources to respective holding-times is constructed in linear time in the size of the learning data. Therefore, using less data also simplifies the computation of the mapping. Another observation is that the Web sites represented in our logs were fairly static; therefore, a single computed policy was effective for the total period of 3 months. We expect more dynamic sites to benefit from more frequent re-computation of the policies.
 |
 |
 |
We proposed and evaluated several adaptive policies for managing persistent connections at HTTP Web Servers. We concluded that a policy which determines holding-times based on the requested URL outperforms other policies and significantly improves over fixed-length holding-times (LRU). Beyond connection management, our methodology of deriving policies is general and may find applications in other domains.
We suggest several extensions for future research. Our evaluation assumed uniform connection-establishment costs. Varying costs, however, can support several quality of service classes or capture perceived-latency that varies with different network RTTs. Under varying establishment costs, the objective is to optimize trade-offs of total open-time and combined connection establishment costs. An analogous extension for document caching is when documents have varying fetching costs. In this context, Young [37,38] proposed a generalization of LRU termed GreedyDual. An experimental study on Web proxy traces was performed in [9]. GreedyDual generalizes LRU and can be adopted for connection management. The MPG policy extends to handle varying establishment costs [10]. Thus, our attribute-based policies can be generalized as well.
Our policies are by and large Markovian, in the sense that holding-time depends on attributes of the preceding requests. Such policies are simple to represent and deploy, and achieved good performance. One obvious question is the gain from extending the viability of holding-times beyond the next request.
Our study focused on connection management at Web servers. HTTP/1.1, however, allows both server and client to unilaterally terminate a connection. And indeed, connection management is deployed at proxy servers and browsers as well. Popular browsers seem to deploy different connection-management policies: Internet Explorer uses a fixed 60 seconds timeout for idle persistent connections whereas Netscape Navigator uses an LRU-managed fixed-size cache of 15 connections [36]. If connections are well-managed at every host, the busier party is likely to initiate termination. Busy proxy servers support TCP connections on behalf of many users; and proposals for HTTP-NG [22] support connection re-use across users. A recent study indicates that connection caching and re-use at proxy caches may reduce user-perceived-latencies more than document caching [16] (This study was based on a fixed holding times of 30 seconds). Thus, proxy-side connection management emerges as an important challenge.
Connection management at proxy servers differs in several respects from server-side management: Both request time and the time response is received are available to the HTTP session layer and can be used by the policy. There is more per-user information available, since all of each user's activities, across all servers, are viewed by the proxy, but there is considerably less per-resource or per-server information. Hence, the resource-based policy that was very effective for server-side management is not likely to be effective at the proxy's end, client-based policies, however, may be effective. Another avenue is to bridge the server-client information gap using piggybacking techniques as proposed in [13].
In principle, the two-sided control of each persistent connection could lead to global under-utilization. Accommodating a new connection may cause the closing of two existing connections, one at each end. Moreover, a connection closed by one end may be a priority at the other end. Such interactions suggest studying the global behavior of local connection management algorithms. Recently, Cohen et al [11] proposed a theoretical model for connection caching. Using this model they prove bounds on the competitive-ratio of local algorithms such as LRU against the optimal offline (not local) algorithm.
http://www.apache.org.
http://www.usenix.org/events/usits97.
http://www.ipservices.att.com/wss/hosting.
ftp://ds.internic.net/rfc/rfc2068.txt.
http://www.cs.cornell.edu/skeshav/doc/94/2-16.ps.
http://www.research.digital.com/wrl/techreports/abstracts/95.4.html.
http://www.cs.wisc.edu/~cao/papers/persistent-connection.html.
This document was generated using the LaTeX2HTML translator Version 97.1 (release) (July 13th, 1997)
Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 1 -link 4 -show_section_numbers persistent.tex.
The translation was initiated by Edith Cohen on 3/4/1999